
Table of Contents
Base
-- 行注释
--[[
块注释
块注释
--]]
为了方面阅读,可以约定
- 常量:全大写和下划线,如 MY_CONSTAND
- 变量:首字母小写,如 myVariable
- 全局变量:首字母为g,如 gMyGlobal
- 函数名:首字母大写,如 function MyFunc()
控制结构
if then else
if a < 0 then a = 0 end
if a < b then
return a
else
return b
end
当条件比较多时,可以使用elseif, 避免重复使用end
if op == "+" then
return a + b
elseif op == "-" then
return a - b
elseif op == "*" then
return a * b
elseif op == "/" then
return a / b
else
error("无效操作")
end
while
a = {1,2,3,4}
local i = 1
while a[i] do
print(a[i])
i = i+1
end
repeat
一直重复直到满足某个条件
a = {1,2,3,4}
local i = 1
repeat
print(a[i])
i = i+1
until a[i] == nil
数值型 for
语法定义如下
for var = exp1 ,exp2 , exp3 do
something
end
var 的值从 exp1 变化到 exp2 之前,每次执行 something,并在每次结束之后,将步长(step),也就是exp3增加到var上。exp3可选,当不对exp3进行设置时,lua会默认该值为1。
另外,值得注意的是var 是局部变量,即循环结束后就会销毁。
for i = 1 ,max do
print(i)
end
泛型 for
-- 遍历列表 ,index 和 value
for i,v in ipairs(table_name) do
print(i,v)
end
-- 遍历表键值对 , key 和 value
for k,v in pairs(table_name) do
print(k,v)
end
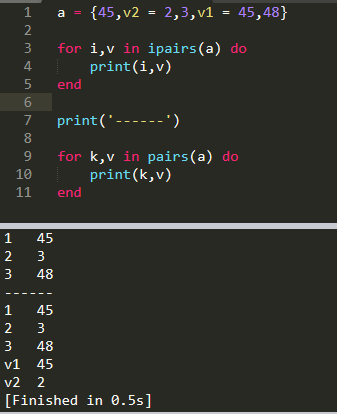
值得注意的是,它们的机制 当使用
ipairs时,如果表中的值设置了键,则不会打印出来,即ipairs只获取键为整型的元素,并且和在表中的先后顺序一致当使用
pairs时,会输出所有元素,但是,不能保证元素出现的顺序,就算一样的代码每次执行输出的结果都可能不一样。
函数
普通函数定义
function function_name( ... )
-- body
end
表的函数成员定义,通常我们都会有访问当前表的其它成员的需求,因此,lua为我们提供了self这个关键字,用来访问自身。有两种定义方式,同时,也有两种调用方式,根据自己喜好来使用。
b = {v = 12}
-- 第一种函数定义方式
b.funcA = function (self )
print(self.v)
end
--b.funcA() -- =>Error,self为nil,试图从nil值访问v报错
b:funcA()
b:funcA(b)
-- 第二种函数定义方式
function b:funcB()
print(self.v)
end
b:funcB()
b.funcB(b)
局部变量
这里需要注意的是变量的生命周期,因为lua中的变量默认是全局的,尽管很方便,但也会很快给我们带来一些困扰,特别是脚本也来越多已经代码越来越长,你不可能清楚的记住所有变量并且保证没有同名,稍有不慎就会覆盖原变量,因此,尽可能使用局部变量,全局变量使用容易辨别的命名方式,如前面提到的g开头命名。
局部变量的声明是
local myValue
local myValue2 = 3
局部变量的有效范围
function MyFunc()
local var1 = 7 --var1 在函数执行完毕后销毁
if var1 < 10 then
local var2 = "Hello world" -- var2 在if语句块执行完毕后销毁
print(var2)
end
print(var2) -- 这里会输出nil 因为var2 已经被销毁
end
参数
有限参数
--无参
function function_name()
-- body
end
-- 多个参数
function function_name(v1,v2)
-- body
end
可变参数
function add( ... )
local s = 0
for i,v in ipairs{...} do
s = s + v
end
return s
end
print(add(3,4,5,6,7))
在调用函数时,如果输入的参数少于定义的,Lua会默认用nil补齐;如果多余定义的,则摒弃。
返回值
lua可以有多个返回值
function Calc( a,b )
return a + b, a- b
end
v1,v2 = Calc(2,3)
print(v1,v2)
类似的,在调用函数时,如果接收的变量少于返回的,Lua会则摒弃掉;如果多于定义的,不进行赋值,保持默认值nil
尾调用
调用栈
调用栈主要用来控制程序调用的执行流程,当主程序调用某个子程序时,它会把子程序的所有数据,如子程序用到的局部变量,参数,以及全部操作压入调用栈,最后压入返回地址。程序执行是按照压入顺序执行的,执行完后会返回到调用位置,并释放资源。
如
function add(a,b)
res = a + b
return res
end
-- ...
v1 = 2
v2 = 4
v3 = add(v1,v2)
-- ...
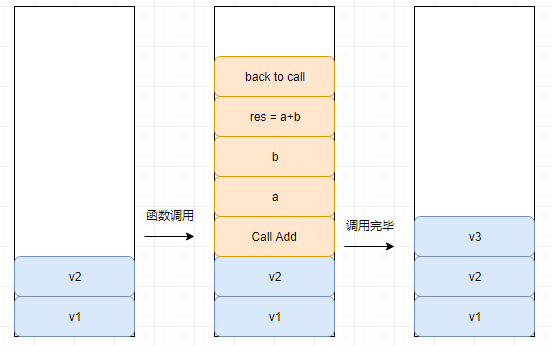
堆栈溢出
堆栈溢出产生的原因是,由于过多的函数调用,导致调用堆栈无法存放这些调用的返回地址。一般在递归中产生,要么是无限递归,要么是过多的堆栈层级(如求解一个NP问题)。前面的图中,每次函数调用都会压入些数据,当嵌套很深很多时,调用栈很快就被消耗完,造成栈溢出。
不过在lua 中,可以在某个函数最终返回时,使用形如 return func(args) end 的调用是尾调用,即该调用执行完毕后可以直接接着原先调用的地方继续,它可以不需要额外的栈空间,即记录返回地址。不过局部变量,参数这些还是需要压入调用栈的。但是,因为尾调用不需要记录返回地址,所以不会发生“栈溢出”的情况,还记得前面栈溢出的定义吧,就是无法压入返回地址导致的错误,叫栈溢出。但是因为其他数据的压入还是有的,不过,在编辑阶段会把内部变量进行合并,所以尾调用的优化可以说,优化了减少记录信息(内存的使用),以及不会出现“栈溢出”错误,但是内存的消耗还是不可避免的(相对来说已经减少了许多),相当于紧接着调用的地方继续执行,然后再原来的函数执行完毕时,全部一起释放。
function f()
m = 1
n = 2
return g(m + n)
end
f()
// 等同于
function f()
return g(3)
end
f()
// 等同于
g(3)
参考尾调用优化
闭包
闭包 ,就算一个函数 加上可以使该函数正确范围非局部变量所需的其他机制(在lua中,就算upValue)。 在lua中的技术实现中,只有闭包没有函数,函数本身只是闭包的一种原型。不过为了避免混淆,还是按照习惯把他们区分开。
但一个函数(或匿名函数)使用到本函数外部的变量时,就会产生一个闭包,该闭包为它创建了方法外部变量的映射。
function newCounter()
local count = 0
return function ( )
count = count + 1
return count
end
end
c1 = newCounter() --保存返回的匿名函数的引用,通过c1()来调用该匿名函数
print(c1()) -- =>1
print(c1()) -- =>2
c2 = newCounter() -- c2是创建了一个新的闭包,和c1不一样,拥有不同的上值
print(c2()) -- =>1
print(c1()) -- =>3
print(c2()) -- =>2
表
table 是lua中最强大也是最容易照成困扰的数据类型。通过它,表示普通数组、序列(表示用{1,…,n}的正整数集做索引的表)、符号表、集合、记录(结构)、图、树等等。
表构造
a = {1,v2 = 2,3}
b = {"s",5,nil}
c = a
print((a == b)) -- => false
print((a ~= b)) -- => true
print((a == c)) -- => true
print(a.v2) -- => 2
print(c.v2) -- => 2
c.v2 = 100
print(a.v2) -- => 100
print(c.v2) -- => 100
注意,当我们使用直接初始化表时,即在构造表的时候就赋值,有几个情况是不允许的
- 不能显式指定整型索引,即
a = { 1 = "yimi" ,"2" = 18 }这个表的两个元素的声明都是无效的,编译无法通过- 只能使用a[1] = “yimi”,a[2] = 18,这种方式来显式的指定特定索引的值
- 另外
a.name等价于a["name"]的情况只有 表a被当做结构体来使用的时候才有效- 如
a = { name = "yimi" ,age = 18 } - 当a 是一个列表或混合结构时,这个定义就不再有效
- 如
a = {1,2, 3, 4, 5,6}, a[5] 输出 5 , a[‘5’] 输出 nil - 但是如果想要使用字符串作为间输出和a[5]一样的值,可以使用
a[tonumber('5')],把字符串转化为数值类型
- 如
- 如
表遍历
对于序列,我们使用数值型for进行遍历,通过Lua提供的获取序列长度的操作符#,对于字符串,该操作符返回字符串长度,对于表,该操作符返回对应的序列的长度。
a = {1,2,3,4,5}
print(#a) -- => 5
a[4] = nil
a[5] = nil
print(#a) -- => 3
b = {1,nil,nil,4,nil}
print(#b) -- => 1
注意 表中如果有空洞时,即某些元素为nil,这时返回的长度并不可靠.因此,在处理有空洞的列表时,应该显示的把列表长度保存起来. 还有,lua的序列的索引是从1开始的,而且,可以是负数
使用pairs 迭代器遍历表时,不能保证遍历过程中元素的出现顺序。对于列表来说,可以所有 ipairs 迭代器,此时,lua会保证遍历是按顺序进行的。另外,使用数值型for var = i,lenght do something end 也是可以保证顺序的
元表
Lua中的每个值都可以有一个元表 。这张表定义原始值在特定操作下的行为。当你想要改变一个值在特定操作下的行为,可以在它的元表中设置对应域。
元表创建和获取
a = {}
setmetatable(a,{}) -- 使用一个空表作为元表,也可以使用其它已经设置好的表,元表是可以复用的
mt = getmetatable(a) -- 如果没有设置元表就尝试获取元表,会得到一个nil返回值
print(mt)
上面也可以简写为
a = setmetatable({},{})
mt = getmetatable(a)
print(mt)
元方法
元表中的键对应着不同事件名,键关联的值称为元方法。
| 事件名 | 触发操作 | 说明 |
|---|---|---|
| __add | a+b | 对非数字类型的变量进行加操作,检查__add方法的定义,首先检查a有没有,没有就继续检查b,一旦找到定义,就马上把两个操作数传递给该方法,如果都没有定义,就抛出错误 |
| __index | table[key] | 当table 不是表 或者 表table不存在key这个键时触发,会去读取__index对应的元方法,元方法可以是函数,也可以是一张表。元方法是函数时,以table和key作为参数调用它;元方法是表时,以key去索引这张表的结果(该索引流程和常规流程一样,如果被索引的表没有该键,可能也会触发该表的元方法,如果定义了的话,以此类推下去)。 |
| __newindex | table[key] = value | 进行索引赋值时,如果表中没有该键,这个事件就会被触发。和__index方法一样,元方法是函数时,以table,key,value作为参数调用;元方法是表时,则对该表进行索引赋值操作(类似的,也可能会触发另一次元方法)。另外,一旦有了__newindex元方法,lua就不再做最初的赋值操作了。(如果有必要,可以在元方法内部使用rawset赋值) |
| __call | 函数调用操作 table(args) | 当尝试对一个非函数的值使用函数调用的形式时,会操作该值的__call元方法,如果找到定义,就调用这个方法,table作为第一个参数,args依次作为后面参数 |
面向对象编程
思路,利用元表的特性来创建一个类,拥有其他高级语言的类的功能,如继承
定义一个Object表,作为最基础的对象,其它对象都从此对象开始派生。
-- ==================
-- Class.lua
-- ==================
Object = {}
--构造函数
Object.__call = function (type)
local instance = {}
instance.class = type
setmetatable(instance,type.prototype)
return instance
end
Object.__index = Object;
--借鉴javacript的prototype机制,把类型和实例定义分离,让所有的实例属性和实例方法定义到prototype中
Object.prototype = {
__gc = function (instance)
print(instance,"destroy")
end,
__tostring = function(instance)
return '['..instance.class.name..' object]'
end
}
Object.prototype.__index = Object.prototype
--子类继承
function Object:subClass(typeName,subBody)
--以传入类型名称作为全局变量名称创建table
_G[typeName] = {}
--设置元方法__index并绑定父级类型元素作为元表
local subType = _G[typeName]
subType.name = typeName
subType.base = self --让子类保存基类引用
subType.__call = self.__call --通用的构造函数
subType.__index = subType
setmetatable(subType,self) -- 添加了__index键值对后,把自己作为子类的元表
--创建prototype并绑定父类prototype作为元表
subType.prototype = subBody or {}
subType.prototype.__index = subType.prototype
subType.prototype.__gc = self.prototype.__gc
subType.prototype.__tostring = self.prototype.__tostring
setmetatable(subType.prototype,self.prototype)
return subType
end
--=======================
--基类操作
--访问基类属性 class.base.prototype.XX
--访问基类方法 class.base.prototype.XXFunction
--=======================
-- 声明一个People类
Object:subClass('People')
People.prototype.name = 'yimi'
local p = People()
print(p)
People:subClass('Chinese')
Chinese.prototype.skin = 'yellow'
local ch = Chinese()
print(ch,ch.name,ch.skin)
关于
self.__index = self的解疑 之前一直在这个地方感觉很迷惑,不懂得其含义到底是什么。绞尽脑汁都想不明白。 冷静了一下,重复的看了又看,突然间想明白,原来是自己之前一直误解了这个self 之前一直想错的原因是
之前的理解就像这个样子
a = {}
setmetatable(a,{_index = a})
print(a.v2) -- 当尝试访问不存在的变量时就会报错 :'__index' chain too long; possible loop
把它变成下面这个形式
a = setmetatable({},{})
mt = getmetatable(a)
mt.__index = a -- 盲点,自己误以为这个self表示的是自己的元表
print(a.v2)
正确的是把mt改为 a
a = setmetatable({},{})
mt = getmetatable(a)
a.__index = a
print(a.v2)
这样子做是为了把a作为其它子类的元表,当其它子类没有找到元素时,就会尝试从自己的元表,也就是a中寻找,如果在a中也找不到,就会从a的元表中找,从而实现了继承类
表的标准库
| API | 说明 |
|---|---|
| table.insert(t,x) | 向序列的末尾位置插入一个元素 |
| table.insert(t,i,x) | 向序列的指定位置插入一个元素 |
| table.remove(t) | 移除序列最后一个元素 |
| table.remove(t,i) | 移除序列指定位置的一个元素 |
| table.move(t,i,j,k) | 把序列从i,j位置的元素移动到位置k,值得注意的是,这个函数实质上是拷贝创作,如果在原序列内,会覆盖原来的值,超过序列,则增加相应长度 |
| table.pack(…) | 用来把可变长参数打包成表返回,相当于 {…},但是该函数返回的表中有一个额外的字段”n”,该字段记录了表的长度 |
| table.unpack(t) | 把数组拆分,如 a,b,c = table.unpack{1,2,3} ,或者 t = {1,2,3}, a,b,c = table.unpack(t) |
函数库
数学库 math
| 函数 | 输入 | 输出 | 说明 |
| math.floor(x) | 3.3 | 3 | 向下(负无穷)取整 |
| -3.3 | -4 | ||
| math.ceil(x) | 3.3 | 4 | 向上(正无穷)取整 |
| -3.3 | -3 | ||
| math.modf(x) | 3.3 | 3,0.3 | 返回两个值,第一个是向零取整的结果,第二个是小数部分 |
| -3.3 | -3,-0.3 | ||
| math.random(x) | [0,1) | 返回[0,1)范围内的伪随机数实数 | |
| 整型n | [1,n] | 返回[1,n]范围内的伪随机整数 | |
| 整型n,m | [n,m] | 返回[n,m]范围内的伪随机整数 | |
| math.randomseed(x) | os.time | 设置随机种子,如果不设置,则每次启动时都会产生相同的随机数序列,可以使用当前系统时间作为种子 |
如果想要对最近的整数取整,可以简单使用 math.floor(x+0.5),但是,对于数值很大的情况就不适用了
自定义round函数
-- 向上取整
function round_up(x)
local f = math.floor(x)
if x == f then
return f
else
return math.floor(x+0.5)
end
end
-- 向最近的整数取整
function round_nearest( x )
local f = math.floor(x)
if (x == f) or (x % 2.0 == 0.5) then
return f
else
return math.floor(x + 0.5)
end
end
print(round_up(2.3)) -- =>2
print(round_nearest(2.3)) -- =>2
print(round_up(2.5)) -- =>3
print(round_nearest(2.5)) -- =>2
print(round_up(2.8)) -- =>3
print(round_nearest(2.8)) -- =>3