
Table of Contents
在华容道的案例中,我们发现,总是无法得到最短路径,甚至得到过300多步骤的解决方案,这样一个结果显然难以接受。思考了一下,应该如何进行改进呢。
突然想起一句话,”广度优先搜索总是可以找到最短路径”,但是如果只是简单的广度搜索可能会有很多没用的分支,因此需要使用启发函数来进行优先选取。
重新复习一遍寻路算法中的几个算法和概念吧。
先是简单的广度优先搜索。 在寻路算法中的表现就相当于从起始点开始往四周进行扩散,直到找到目标点,类似于涟漪往四周扩散。哪个扩散点找到就开始回溯该节点,从而得到路径。
然后是迪捷斯科拉算法。 是在广度优先搜索的基础上进行了调整,每个节点对自身所有可达节点进行计算并加入已探索队列,对于已经在已探索队列中的节点,比较其记录的长度,如果当前节点抵达该节点的路径长度更加短,更换该节点的前继节点为当前节点,并且更新该节点的最短路径长度记录。
接下来是贪心算法,与其朝着四周无目的的扩散,不如一开始就确定目标进行扩散,所以就以曼哈顿距离来权衡,优先选择曼哈顿距离小的点进行扩散,即每次添加新的节点到探索队列时,会按照其曼哈顿距离的大小把它放到队列的合适位置。
最后是A。有时候,贪心算法会失效,即不那么准确,当我们考虑每个节点有移动成本时,这时候的曼哈顿距离就不足以描述选择的权重了,因此,添加上路径成本的考虑,就成为了我们的A算法,贪心算法和A*算法其实差不了多少,就是启发公式不同而已,一个是简单的曼哈顿距离判断,另一个是曼哈顿距离加上路径成本的判断。
好了,复习完毕,回到HTN的优化上,因为在算法递归时,是一直将某个任务不断的分解下去,所以是一个深度优先的算法,要把之前写的深度优先算法进行调整,改为宽度优先。就需要使用一个容器进行排序和保存。
大概思路是
AddtoTaskList(root)
function DoPlan(plan)
task = GetTask()
if task == nil then
return {}
end
if task.isPrimitive then
action = GetAction(task)
return DoPlan(a·plan)
else
methods = GetMethods(task)
methods = PickUp(methods) -- 过滤无用方法,并返回排好序的方法
-- 把所有方法转为其子任务压入任务队列
tasks = ConvertToTasks(methods)
AddtoTaskList(tasks)
return DoPlan(plan)
end
end
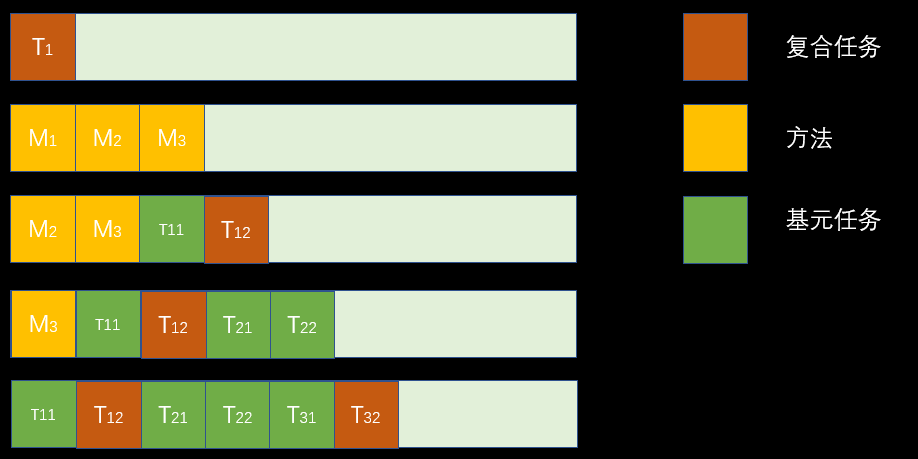
不过,在开始实现的时候发现了不对劲的地方,这接近是寻路算法的思路,没有充分考虑到HTN的特性,分层任务网络,多解决方案。因此,需要对其进行改造。也就是下面这个样子。
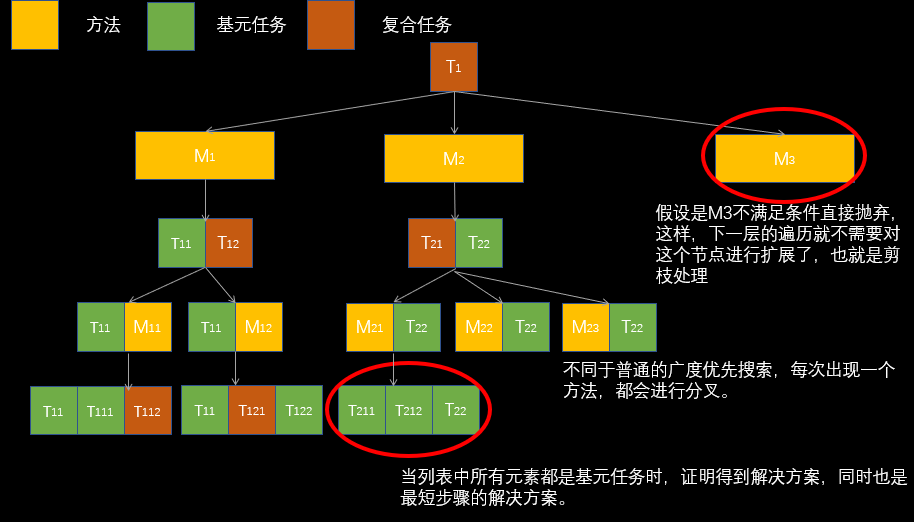
不过,并不是说前面的算法就不能用了,我们还是需要用到这个思路,把每个分支当成一个整体进行搜索
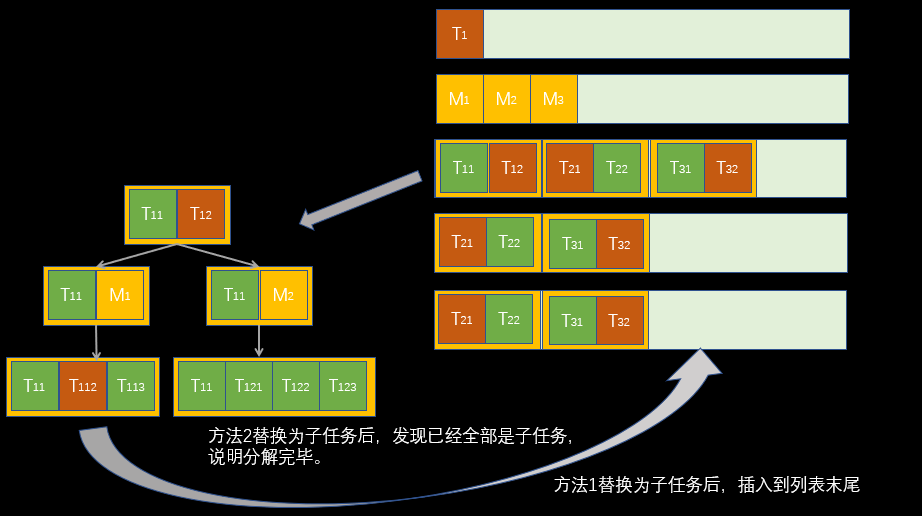
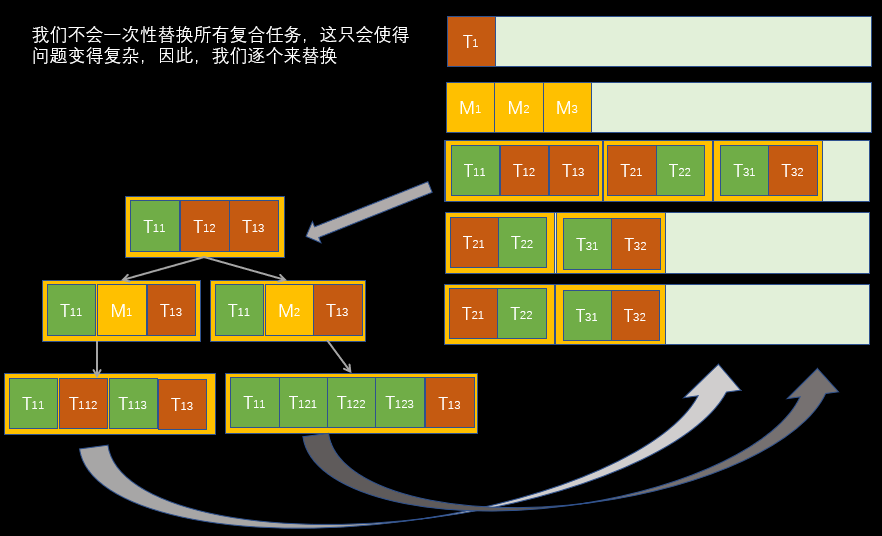
另外,对于有多个复合任务时,我们每次只处理一个,其他的留到下一次处理,来简化逻辑。
--==========================
-- 伪代码
--==========================
AllPlans = { NewPlan(root)}
function DoPlan(AllPlans)
plan = AllPlans.Pop()
task,task_index = plan.GetCompoundTask()
if task == nil then
return plan
end
methods = GetMethods(task)
methods = PickUp(methods) -- 过滤无用方法,并返回排好序的方法
for m in methods do
worldstates = copy(plan.worldstates)
subtasks = m.GetSubtask()
for t in subtasks do
if t.IsPrimitive then
action = GetAction(a)
isNewWorldState = ApplyActionEffects(worldstates,a)
if not(isNewWorldState) then
--造成重复的世界状态 抛弃此方法
end
end
end
-- 所有此方法的子任务替换该任务,生成新的计划,并加入任务队列
newPlans = Replace(plan,task_index,subtasks)
-- 这里可以进行优化,使用启发函数将新任务插入合适的位置
AllPlans.Add(newPlans)
end
return DoPlan(AllPlans)
end
代码实现
--==========================
--Total-Order Breadth First Decomposition
-- 全序广度搜索优先分解
--==========================
function Planner:TBFD(_planList)
if #_planList == 0 then
--print("找不到解决方案")
return
end
if self.Plan ~= nil then
return
end
local plan = _planList[1]
if plan.compoundtask_id == nil then
return
end
table.remove(_planList,1)
local task = plan.tasks[plan.compoundtask_id]
self:AddSubPlans(plan,plan.compoundtask_id,task,_planList)
coroutine.yield()
self:TBFD(_planList)
end
function Planner:ChooseAction(_ws,_task)
local res ,whyfail = IsFitPreconds(_ws,_task.preconds)
if res then
local a = self.Actions:GetAction(_task.taskDecl)
a.name = _task.taskDecl
ApplyActionEffects(_ws,a)--应用行动效果
if self:AddWorldState(_ws) then
return a
else
-- 状态重复
return nil
end
else
-- 条件不满足
return nil
end
end
function Planner:AddSubPlans(_parentPlan,_index,_task,_planList)
local methods = _task.Methods
local fitableMethods = {}
-- 获取可以进行的方法,进行剪枝,过滤没必要的方法
for i, m in ipairs(methods) do
local method = self.Methods:GetMethods(m)
method.name = m
local isfit,whyfail = IsFitPreconds(_parentPlan.worldstates,method.preconds)
if isfit then
table.insert(fitableMethods,method)
else
--print(m.." 不满足条件"..whyfail)
end
end
-- 使用启发式对方法进行排序
if self.Methods.UseHeuristic == true then
for i, v in ipairs(fitableMethods) do
-- 对方法进行评分
self.Heuristic.Calc(_parentPlan.worldstates,v)
end
--开始排序
self.Heuristic.Sort(fitableMethods)
end
--把所有方法的子任务压入OpenTasks,待探索队列
for i, m in ipairs(fitableMethods) do
--获取实例化子任务
--print("======================获取子任务"..m.name)
if m.subtasks ~= nil then
local childtasks = {}
local actions = {}
--为了不干扰世界状态,进行深拷贝
local _ws = table.deepcopy(_parentPlan.worldstates)
for _, v in ipairs(m.subtasks) do
local t = self.Tasks:GetTask(v)
table.insert(childtasks,t)
if t.IsPrimitive then
local a = self:ChooseAction(_ws,t)
if a ~= nil then
table.insert(actions,a)
else
--print("【无法成为行动】"..v)
childtasks = nil
break
end
end
end
if childtasks ~= nil then
local subplan = {
worldstates = _ws,
tasks = table.deepcopy(_parentPlan.tasks),
actions = table.combine(_parentPlan.actions , actions)
}
-- 把制定索引处的任务替换成子任务
table.replace(subplan.tasks,_index,childtasks)
subplan.compoundtask_id = nil
for i = _index, #subplan.tasks do
if not(subplan.tasks[i].IsPrimitive) then
subplan.compoundtask_id = i
break
end
end
if subplan.compoundtask_id ~= nil then
--print("把新的计划放到计划列表的末尾 ,复合任务索引 ="..subplan.compoundtask_id)
-- 把新的计划放到计划列表的末尾
table.insert(_planList,subplan)
else
print("全部为基元任务,放到第一位")
table.insert(_planList,1,_parentPlan) --放到第一位
end
end
else
-- 遇到结束状态
print("遇到结束状态===============================================================")
_parentPlan.compoundtask_id = nil -- 肯定不会再有复合任务了
table.remove(_parentPlan.tasks,_index)
_planList = nil
self.Plan = _parentPlan.actions
return
end
end
_parentPlan = nil
end
准备扩展功能
- AI对世界的感知,如视觉,听觉
- 为此,给AI提供感知器用来感知世界中某些信息
- AI短期记忆
- 有种傻傻的AI,如一旦敌人离开视野,会马上回到巡逻,然后一看到敌人,又开始追击,因此,需要一种惯性来避免状态的来回切换。即,短期内,不会在回到该状态
- 多代理
- 让尽可能多的代理智能体同时进行规划
- 对于RPG这种,一个场景内能够支持100个智能体已经足够
- 而对于RTS这种,动则上千单位,应该尽可能的分层设计
- 如,由上层战略层进行宏观调控,个体Ai只进行一些简单Ai和上层指示的接受
- 调试器
- 提供计划查看
- 计划模拟
- 运算消耗